Clustering with sample weights¶
Like HDBSCAN, PLSCAN supports weighted samples as input.
[1]:
import numpy as np
import matplotlib.pyplot as plt
from fast_plscan import PLSCAN
plt.rcParams["figure.dpi"] = 150
plt.rcParams["figure.figsize"] = (2.75, 0.618 * 2.75)
data = np.load("data/clusterable/sources/clusterable_data.npy")
The leaf tree without sample weights has many leaf-clusters:
[2]:
c = PLSCAN().fit(data)
c.leaf_tree_.plot(leaf_separation=0.15)
plt.show()
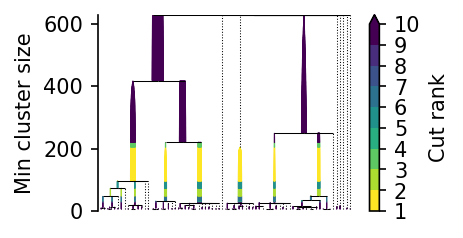
Using sample weights below 1, the leaf tree with weights has fewer leaf-clusters.
[3]:
c = PLSCAN().fit(data, sample_weights=np.random.rand(data.shape[0]))
c.leaf_tree_.plot(leaf_separation=0.15)
plt.show()
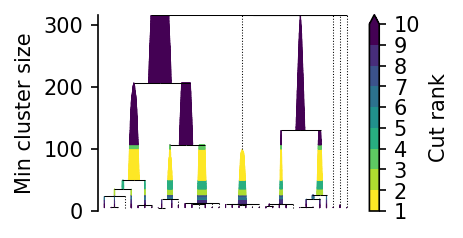
Unlike HDBSCAN, PLSCAN uses the unweighted number of neighbors to compute core distances (for now).